1. Druid简单介绍
Druid是阿里巴巴开源的数据库连接池,号称是Java语言中最好的数据库连接池,能够提供强大的监控和扩展功能。
GitHub地址:https://github.com/alibaba/druid
优点:
① 可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
② 替换DBCP和C3P0,Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
③ 数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDriver和DruidDataSource都支持PasswordCallback。
④ SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。
⑤ 扩展JDBC,如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter-Chain机制,很方便编写JDBC层的扩展插件。
2. druid基础配置
2.1 创建基本的SpringBoot项目
此次使用的是基于Mysql与Postgresql的双数据源搭建的demo。(双数据源搭建查看上一篇博客内容)
2.2 导入jar
之后导入druid.jar。Druid 0.1.18之后版本都发布到maven中央仓库中,所以你只需要在项目的pom.xml中加上dependency就可以了。
1 | <!--druid-demo所需jar,本demo使用的是log4j来做日志记录--> |
2.3 设置druid相关配置
1 | spring: |
2.4 配置Druid监控统计功能
基于Druid的Filter-Chain扩展机制,Druid提供了3个非常有用的具有监控统计功能的Filter:
StatFilter用于统计监控信息;
WallFilter基于SQL语义分析来实现防御SQL注入攻击;
LogFilter 用于输出JDBC执行的日志。
如果在项目中需要使用Druid提供的这些监控统计功能,可以通过以下两种途径进行配置。
①方式一:基于Servlet 注解的配置
对于使用Servlet 3.0的项目,在启动类上加上注解@ServletComponentScan 启用Servlet自动扫描,并在自定义的DruidStatViewServlet/DruidStatFilter 上分别加上注解@WebServlet/@WebFilter 使其能够被自动发现。
DruidStatViewServlet.java
1 | /* |
DruidStatFilter.java
1 | /* |
之后在启动类加上@ServletComponentScan:
1 | import org.springframework.boot.SpringApplication; |
②方式二
使用Spring的注解@Bean对自定义的Servlet或Filter进行注册,Servlet使用ServletRegistrationBean进行注册,Filter使用FilterRegistrationBean进行注册。
1 | import com.alibaba.druid.support.http.StatViewServlet; |
此demo采用的第二种方式(注释启动类的//@ServletComponentScan)。
3. Druid使用log4j2进行日志输出
3.1 pom.xml中springboot版本依赖
1 | <!--Spring-boot中去掉logback的依赖--> |
3.2 log4j2.xml文件中的日志配置(完整,可直接拷贝使用)
1 | <?xml version="1.0" encoding="UTF-8"?> |
4.3 配置application.yml
1 | # 配置日志输出 |
4. 测试与运行
4.1 相关实体类创建
相关数据库表、数据创建,以及相关dao,service,controller创建。(本demo采用上一个博客的相关类)
系统结构目录如下:
4.2 测试
swagger上查询结果:
1 | [ |
然后访问:http://localhost:8081/druid/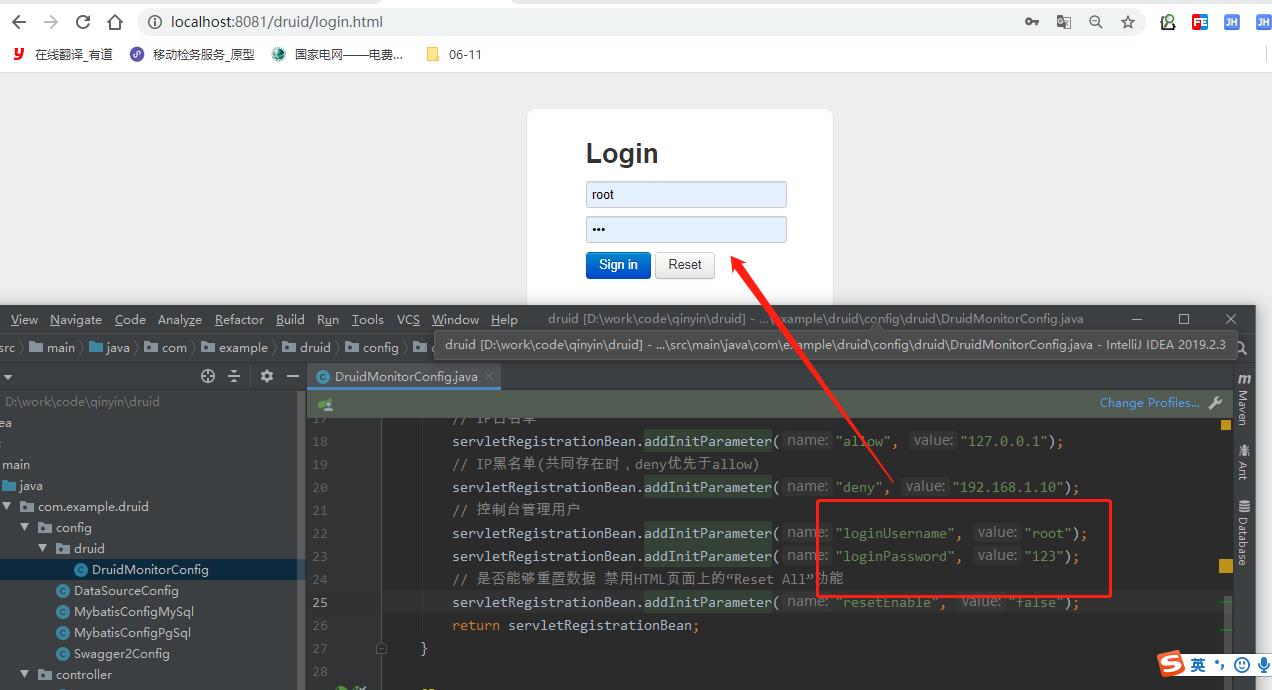
大概就是下面这样的图: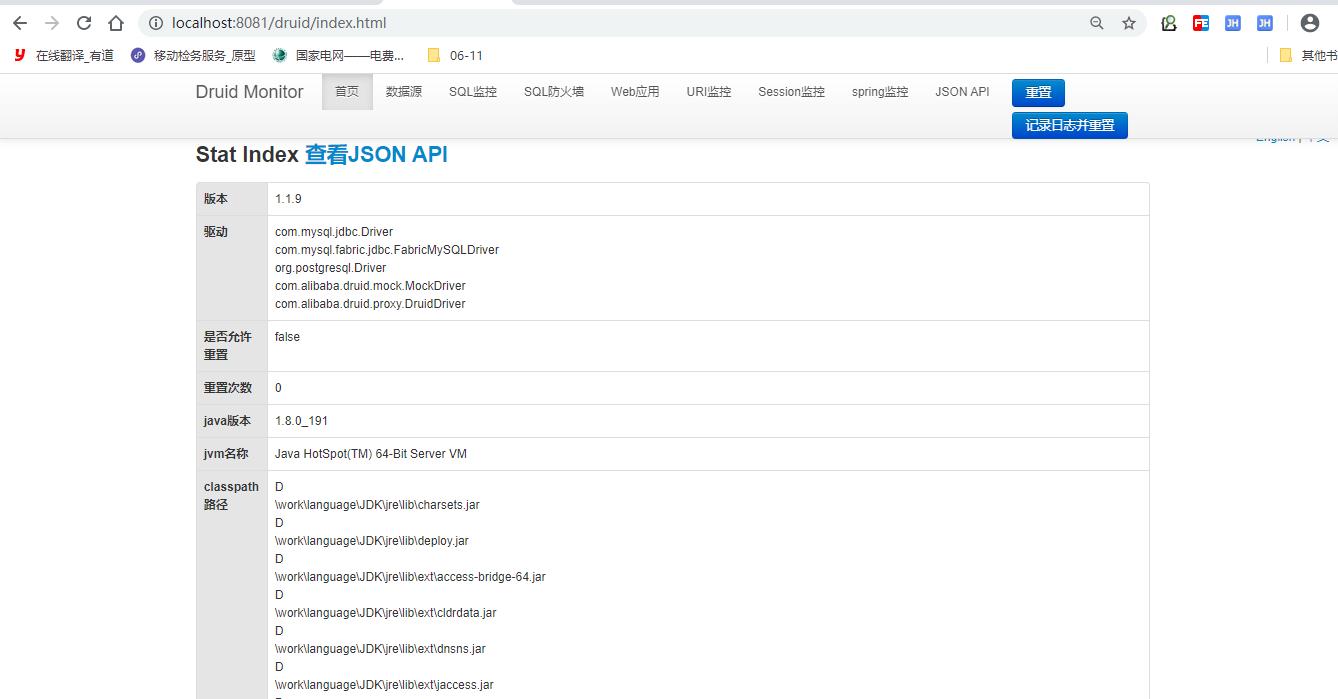
控制日志记录如下:
1 | 2020-06-18 00:11:15.948 INFO 34916 --- [nio-8081-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet' |
5. druid数据库密码加密
本demo只对主数据源MySQL进行了密码加密,对从数据源密码步骤类似。
5.1 密码加密
5.1.1 通过druid-1.0.18.jar提供的ConfigTools工具对密码进行加密:
在druid所在的目录下打开cmd窗口:
1 | #格式:java -cp druid.jar com.alibaba.druid.filter.config.ConfigTools you_password |
5.1.2 配置文件配置加密解密参数
1 | spring: |
需要用到生成的 publicKey 和 password。而privateKey私钥,用于生成密文密码用,不用管。
5.2 配置ConfigFilter
5.2.1 配置文件从本地文件系统中读取
SpringBoot默认是从本项目中的soureces目录中读取,故如果是使用本地application.yml文件中的配置参数,下面的代码可以忽略不添加。而且某些配置SpringBoot会自动注入,不需要手动设置。
1 | try { |
5.2.2 配置文件从远程http服务器中读取
1 | try { |
这种配置方式,使得一个应用集群中,多个实例可以从同一个地方读取配置,集中配置,集中修改,部署更简单。
5.2.3 通过jvm启动参数来使用ConfigFilter
DruidDataSource支持jvm启动参数配置filters,所以可以:
1 | java -Ddruid.filters=./config/application.yml |
5.3 手动密码加密解密
5.1中的加密是通过外部cmd命令生成的密码,5.2是使用druid封装好的解密工具对密文进行解密。但其实也可以通过自定义的代码来实现加密解密。
其实druid的加密解密都是通过ConfigToolsTest.java文件中的encrypt和decrypt方法来实现的。故只要单独调用这两个方法,即可实现自定义加密解密。
1 | public static void main(String[] args) throws Exception { |
可以将手动生成的密码密文与公钥写入配置文件,然后在创建dataSource这个bean的时候,手动解密写入dataSource中。
5.4 相关问题记录
5.4.1 配置 connection-properties 失误
druid官网上的配置是:
1 | connection-properties: config.decrypt=true;config.decrypt.key=${publickey} |
但这样配置会报下面的错误:
1 | 2020-06-18 14:41:39.925 ERROR 6388 --- [nio-8081-exec-1] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException: |
目前不清楚是自己跟官网上的其他配置有出入还是官网错误,暂时没找到原因。但我使用下面的配置,就可以正常访问或查询数据:
1 | connection-properties: config.decrypt=true;config.decrypt.key=${spring.datasource.publickey};password=${spring.datasource.password} |
5.4.2 配置不写入配置文件,而是写入代码中
如果connection-properties: config.decrypt=true;config.decrypt.key=${spring.datasource.publickey};password=${spring.datasource.password}这个配置不写入配置文件,而是在代码中体现:
1 | try { |
会报下面的错误:
1 | 2020-06-18 14:38:14.990 ERROR 24840 --- [reate-248705782] com.alibaba.druid.pool.DruidDataSource : create connection SQLException, url: jdbc:mysql://localhost:3306/yq_mysql?serverTimezone=GMT%2B8&characterEncoding=utf-8&useSSL=false, errorCode 1045, state 28000 |
6. 问题记录
如果在项目中使用的是log4j而不是log4j2,那么可能会出现如下警告:
6.1 log4j警告
在项目运行过程中,有log4j配置缺失警告:
1 | log4j:WARN No appenders could be found for logger (druid.sql.Connection). |
该警告不影响项目正常运行,但如果想要消除警告,有多种方式:
①手动在resources目录下创建log4j.properties配置文件来指定相关log4j参数(网上找的答案,但手动操作过,发现没有效果。也有说是因为SpringBoot中含有logback这个依赖,需要将该依赖解除,自定义的log4j.properties配置才会生效。但也亲自操作过,也没有效果,可能是操作过程中有失误)。
②强制在启动类中设置日志缺失环境
1 | public static void main(String[] args) { |
虽然这种方式解决log4j的警告,但个人感觉日志显示的级别过于详细。且只对主数库MySQL进行详细记录,但对PostgreSQL只是简单的记录。对该日志级别设置暂时没找到方法。
1 | Creating a new SqlSession |
6.2 log4j日志配置文件示例
1 | #此句为定义名为stdout的输出端是哪种类型,可以是 |
7. 知识扩展
7.1 线程池介绍
Java中已经提供了创建线程池的一个类:Executor,而我们创建时,一般使用它的子类:ThreadPoolExecutor
1 | public ThreadPoolExecutor(int corePoolSize, |
这是其中最重要的一个构造方法,这个方法决定了创建出来的线程池的各种属性,下面依靠一张图来更好的理解线程池和这几个参数: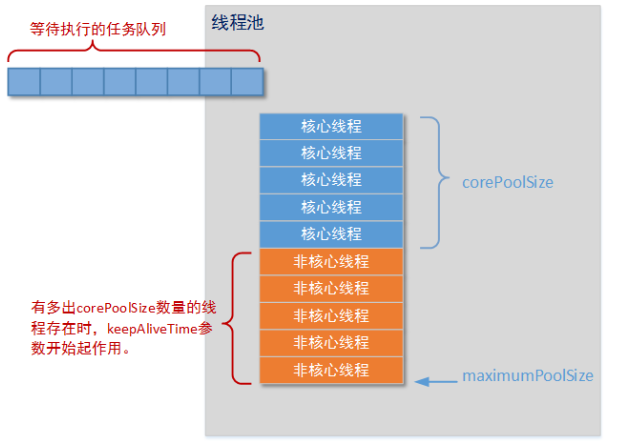
从图中,可以看出,线程池中的corePoolSize就是线程池中的核心线程数量,这几个核心线程,只是在没有用的时候,也不会被回收;
maximumPoolSize就是线程池中可以容纳的最大线程的数量;
keepAliveTime就是线程池中除了核心线程之外的其他的最长可以保留的时间,因为在线程池中,除了核心线程即使在无任务的情况下也不能被清除,其余的都是有存活时间的,意思就是非核心线程可以保留的最长的空闲时间;
util就是计算这个时间的一个单位;
workQueue就是等待队列,任务可以储存在任务队列中等待被执行,执行的是FIFIO原则(先进先出);
threadFactory就是创建线程的线程工厂;
handler是一种拒绝策略,我们可以在任务满了知乎,拒绝执行某些任务。
线程池的执行流程又是怎样的呢?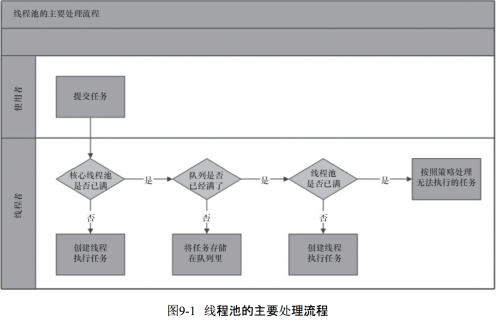
从图中可以看出,任务进来时,首先执行判断,判断核心线程是否处于空闲状态,如果不是,核心线程就先就执行任务,如果核心线程已满,则判断任务队列是否有地方存放该任务,若果有,就将任务保存在任务队列中,等待执行,如果满了,在判断最大可容纳的线程数,如果没有超出这个数量,就开创非核心线程执行任务,如果超出了,就调用handler实现拒绝策略。
handler的拒绝策略:
第一种AbortPolicy:不执行新任务,直接抛出异常,提示线程池已满
第二种DisCardPolicy:不执行新任务,也不抛出异常
第三种DisCardOldSetPolicy:将消息队列中的第一个任务替换为当前新进来的任务执行
第四种CallerRunsPolicy:直接调用execute来执行当前任务
四种常见的线程池:
CachedThreadPool:可缓存的线程池,该线程池中没有核心线程,非核心线程的数量为Integer.max_value,就是无限大,当有需要时创建线程来执行任务,没有需要时回收线程,适用于耗时少,任务量大的情况。
SecudleThreadPool:周期性执行任务的线程池,按照某种特定的计划执行线程中的任务,有核心线程,但也有非核心线程,非核心线程的大小也为无限大。适用于执行周期性的任务。
SingleThreadPool:只有一条线程来执行任务,适用于有顺序的任务的应用场景。
FixedThreadPool:定长的线程池,有核心线程,核心线程的即为最大的线程数量,没有非核心线程